
继承者们第8集:美女被强奷到抽搐的动态图-刘知远详解DeepSeek出圈背后的逻辑:自身算法的创新以及OpenAI的傲慢
·AI如果想要真正赋能全人类,让每个人都能够用得上、用得起大模型和通用人工智能,那么高效性显然是一个非常重要的命题。
·我们认为智能革命显然也要走过一条类似于信息革命的阶段,不断去提高能力密度,降低计算成本,让大模型得以更加普惠。
“DeepSeek R1的开源,让全球的人能够意识到深度思考的能力。这相当于让整个人工智能领域再次迎来了类似于2023年初ChatGPT的时刻,让每个人感受到大模型的能力又往前迈进了一大步。但同时,我们也需要合理地评估DeepSeek本身的重要意义。”清华大学长聘副教授刘知远日前在参与由中国计算机学会青年计算机科技论坛(CCF Young Computer Scientists & Engineers Forum,YOCSEF)策划的直播活动中表示,这场直播的主题为“夜话DeepSeek:技术原理与未来方向”,共同参与话题讨论的还有复旦大学教授邱锡鹏、清华大学教授翟季冬。

直播截图
在这场直播中,刘知远分析了DeepSeek成功出圈带来的启示,并分析了大模型技术未来发展的趋势。刘知远认为,DeepSeek V3展示了如何用十分之一甚至更少的成本完成达到GPT-4和GPT-4o水平的能力,此外DeepSeek R1的出圈也证明了OpenAI犯了“傲慢之罪”——它不开源,不公开技术细节,且定价过高。
以下为刘知远在直播中的观点实录,经本人同意发表:
今天我将从宏观角度为大家介绍DeepSeek R1所代表的大规模强化学习技术,及其基本原理。同时,我们也会探讨为什么DeepSeek R1能够引起如此多的关注。
首先,我们来看DeepSeek最近发布的R1模型,它具有非常重要的价值。这种价值主要体现在DeepSeek R1能够完美复现OpenAI o1的深度推理能力。
因为OpenAI o1本身并没有提供关于其实现细节的任何信息,OpenAI o1相当于引爆了一个原子弹,但没有告诉大家秘方。而我们需要从头开始,自己去寻找如何复现这种能力的方法。DeepSeek可能是全球首个能够通过纯粹的强化学习技术复现OpenAI o1能力的团队,并且他们通过开源并发布相对详细的介绍,为行业做出了重要贡献。
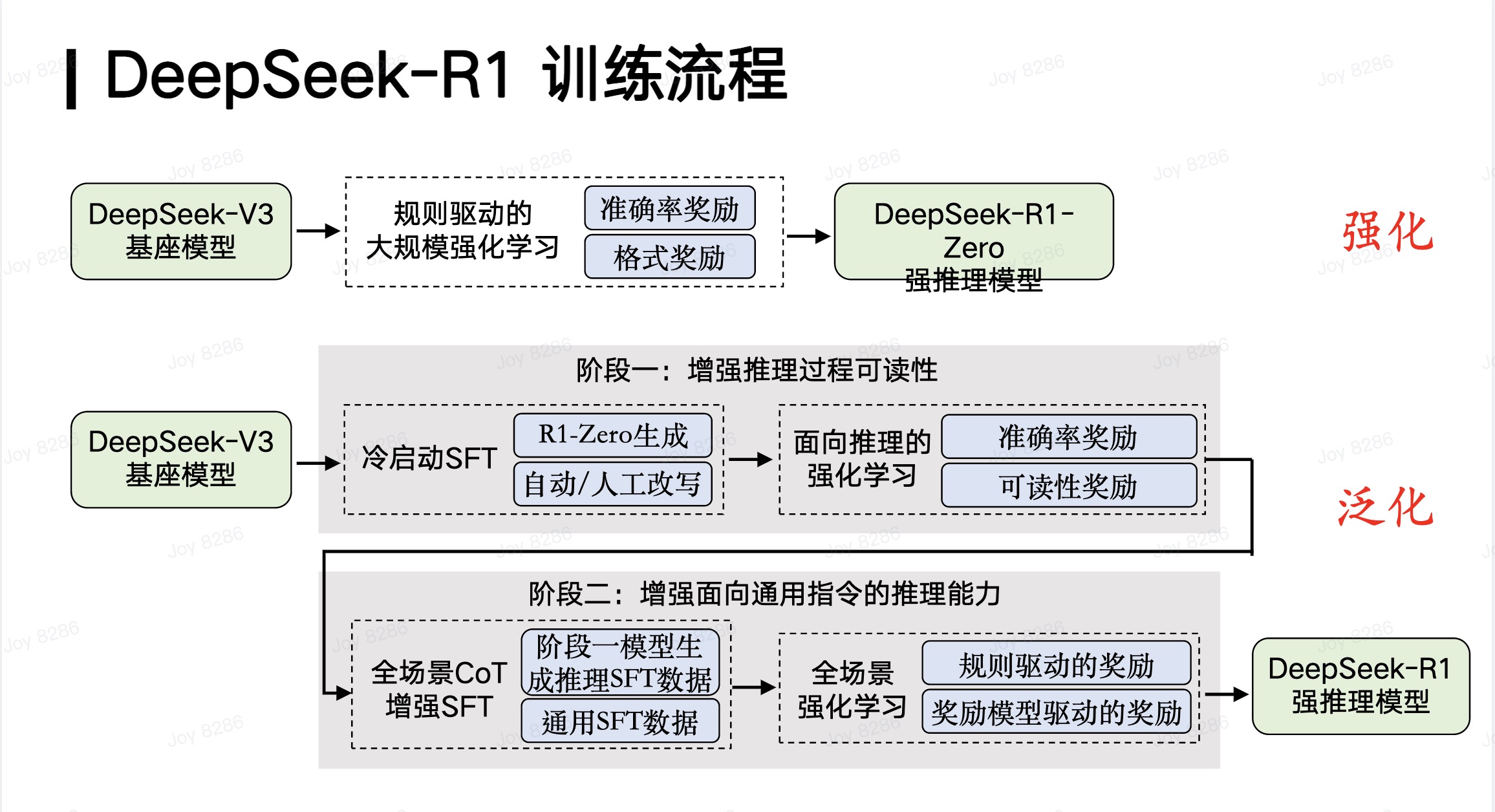
我们可以大致总结了DeepSeek R1的整个训练流程,它有两个非常重要的亮点或价值。首先,DeepSeek R1创造性地基于DeepSeek V3基座模型,通过大规模强化学习技术,得到了一个纯粹通过强化学习增强的强推理模型,即DeepSeek-R1-Zero。这具有非常重要的价值,因为在历史上几乎没有团队能够成功地将强化学习技术很好地应用于大规模模型上,并实现大规模训练。DeepSeek能够实现大规模强化学习的一个重要技术特点是其采用了基于规则(rule-based)的方法,确保强化学习可以规模化,并实现面向强化学习的扩展(Scaling),这是它的第一个贡献。
DeepSeek R1的第二个重要贡献在于其强化学习技术不仅局限于数学、算法代码等容易提供奖励信号的领域,还能创造性地将强化学习带来的强推理能力泛化到其他领域。这也是用户在实际使用DeepSeek R1进行写作等任务时,能够感受到其强大的深度思考能力的原因。
这种泛化能力的实现分为两个阶段。首先,基于DeepSeek V3基座模型,通过增强推理过程的可读性,生成了带有深度推理能力的SFT(Supervised Fine-Tuning,监督微调)数据。这种数据结合了深度推理能力和传统通用SFT数据,用于微调大模型。随后,进一步通过强化学习训练,得到了具有强大泛化能力的强推理模型,即DeepSeek R1。
因此,DeepSeek R1的重要贡献体现在两个方面:一是通过规则驱动的方法实现了大规模强化学习;二是通过深度推理 SFT数据与通用SFT数据的混合微调,实现了推理能力的跨任务泛化。这使得DeepSeek R1能够成功复现OpenAI o1的推理水平。
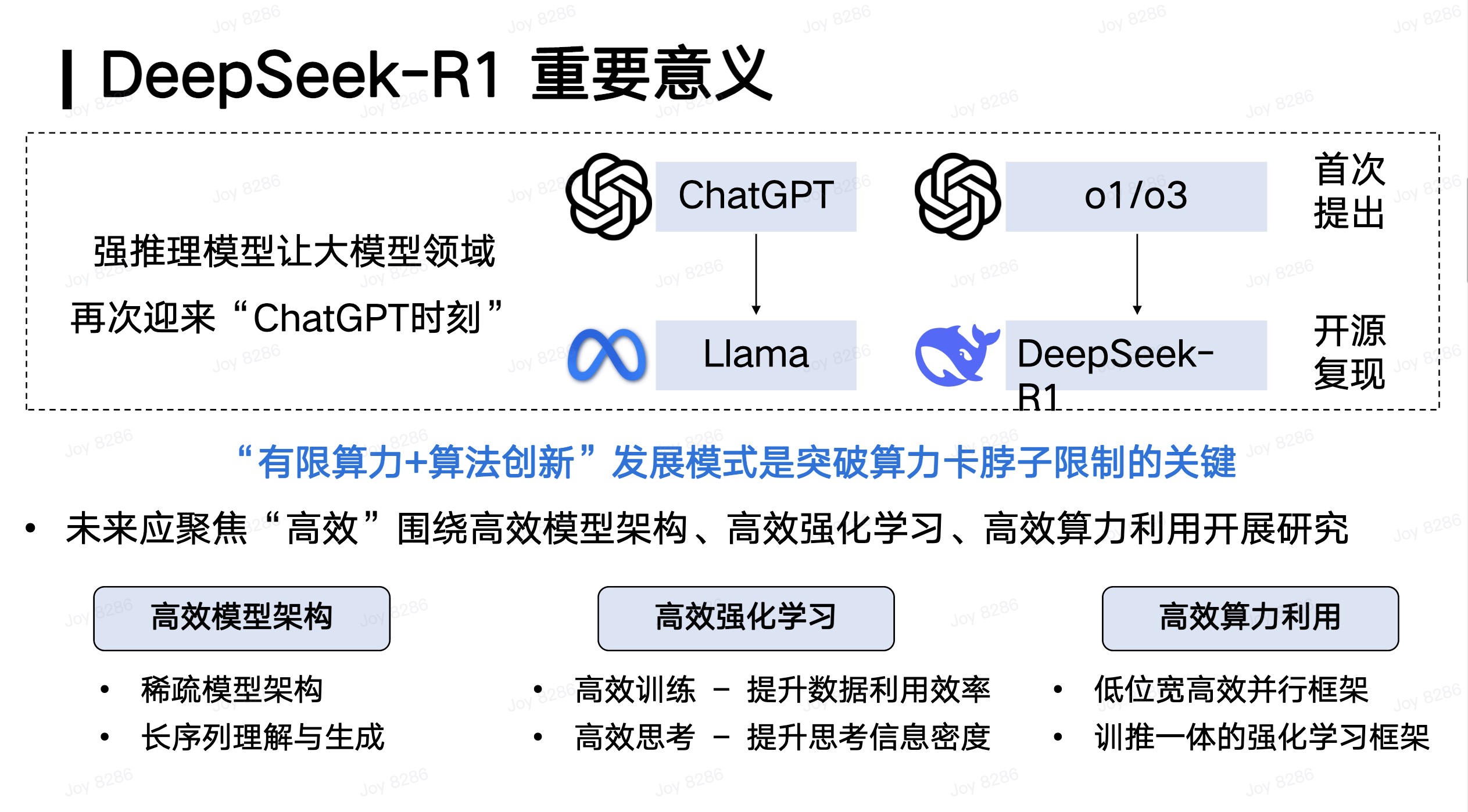
所以,我们其实应该非常重视DeepSeek R1。它由于开源,让全球的人能够意识到深度思考的能力,这相当于让整个人工智能领域再次迎来了类似于2023年初ChatGPT的时刻,让每个人感受到大模型的能力又往前迈进了一大步。但同时,我们也需要合理地评估DeepSeek本身的重要意义。
如果说2023年初OpenAI发布的ChatGPT让全球看到了大模型非常重要的价值,那么这一次的强推理能力其实也是OpenAI在2024年9月发布的o1率先实现的。而DeepSeek R1,我们认为它在历史上更像是2023年Meta的LLaMA。它能够通过开源复现,并且把这些事情全部公开给全球,让大家能够快速地建立起相关能力,这是我们对DeepSeek R1及其重要意义的一个准确认识。
当然,为什么说DeepSeek R1能够取得如此全球性的成功呢?我们认为这与OpenAI采用的一些策略有非常大的关系。OpenAI 在发布o1之后,首先选择不开源,其次将o1深度思考的过程隐藏起来,第三是o1本身采用了非常高的收费。这使得o1无法在全球范围内让尽可能多的人普惠地感受到深度思考所带来的震撼。
而DeepSeek R1则像2023年初OpenAI的ChatGPT一样,让所有人真正感受到了这种震撼,这是DeepSeek R1出圈的非常重要的原因。如果我们进一步将DeepSeek发布的R1和之前的V3结合起来考虑,那么它的意义在于:在非常有限的算力资源支持下,通过强大的算法创新,突破了算力瓶颈,让我们看到即使在有限的算力下,也能做出具有全球意义的领先成果。
这件事对中国AI的发展具有非常重要的意义。当然,我们也应该看到,AI如果想要真正赋能全人类,让每个人都能够用得上、用得起大模型和通用人工智能,那么高效性显然是一个非常重要的命题。
而在这个方面,我们其实有非常多的话题可以去讨论。除了刚才我和邱锡鹏老师提到的强化学习本身需要在未来探索更加高效的方案之外,我们还需要研究出更加高效的模型架构。例如,V3所采用的MoE架构,未来应该也会有许多其他相关的高效架构方案。进一步地,国浩和翟季冬老师稍后也会介绍高效的算力应用等话题。
这其实也是DeepSeek V3和R1带给我们的另一个非常重要的启示。我们也会认为,整个人工智能的发展在未来追求高效性是我们内在的一个使命和需求。
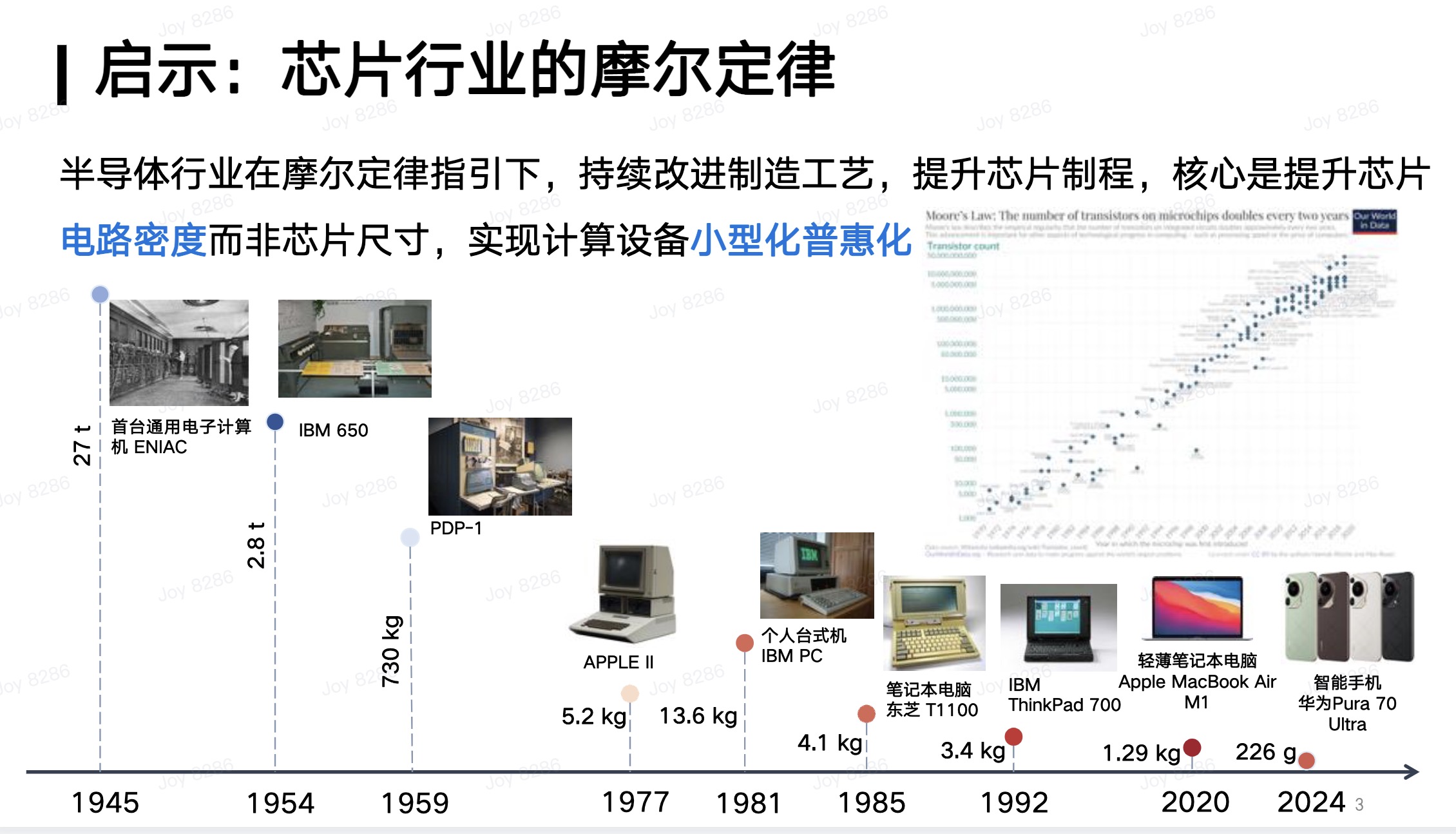
从这个方面,我想适当展开一点来介绍。我们会看到上一次所谓的科技革命,也就是信息革命,其非常重要的内核实际上是计算芯片的发展。在过去80年时间里,计算机从最初需要一个屋子才能装得下的规模,发展到如今每个人手边都有的手机、PC,以及各种各样的计算设备,都可以在非常小的设备上完成非常强大的计算能力。
所有这一切,其实都源于芯片行业在摩尔定律的指引下,不断推进芯片制程,提升芯片电路密度,从而实现计算设备的小型化和普惠化,推动算力的普及。这显然是我们未来追求高效性的一个非常重要的内在需求。
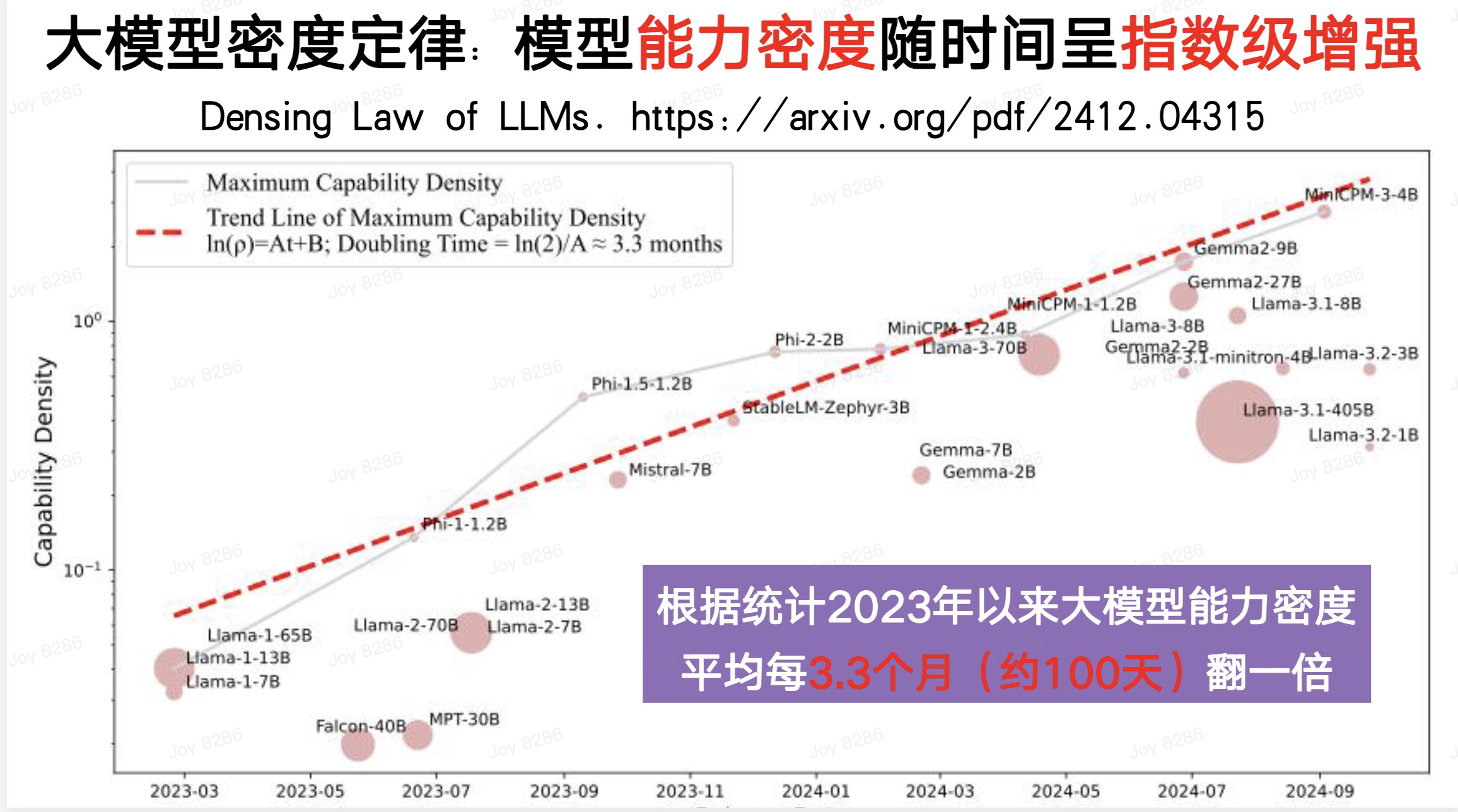
这也是为什么我们在去年特别强调要发展大模型的能力密度。实际上,过去几年我们也能看到类似摩尔定律的现象:大模型的能力密度正以时间的指数级增强。从2023年以来,大模型的能力密度大约每100天翻一倍,也就是说,每过100天,我们只需要一半的算力和一半的参数就能实现相同的能力。
因此,我们相信,面向未来,我们应该不断追求更高的能力密度,努力以更低的成本——包括训练成本和计算成本——来实现大模型的高效发展。 从这一点来看,我们显然可以看到,如果按照能力密度的发展趋势,我们完全可以实现每100天用一半的算力和一半的参数,达到相同的模型能力。而推动这件事情,应当是我们未来发展的使命。

所以,如果我们对标上一个科技革命——也就是信息革命,显然对我们即将到来的智能革命有着非常重要的启示。实际上,在信息革命刚刚开始的时候,IBM的创始人沃森曾认为,世界上不需要超过五台主机就可以满足全世界的计算需求。但到了今天,我们可以看到全球有数十亿、上百亿的计算设备在服务于全人类的社会。
因此,我们认为智能革命显然也要走过一条类似于信息革命的阶段,不断去提高能力密度,降低计算成本,让大模型得以更加普惠。所以,我们会认为AI时代的这些核心引擎,包括电力、算力以及大模型所代表的智力,这种密度定律应该是普遍存在的。我们需要不断地通过高质量、可持续的方式去实现大模型的普惠,这应该是我们未来的发展方向。
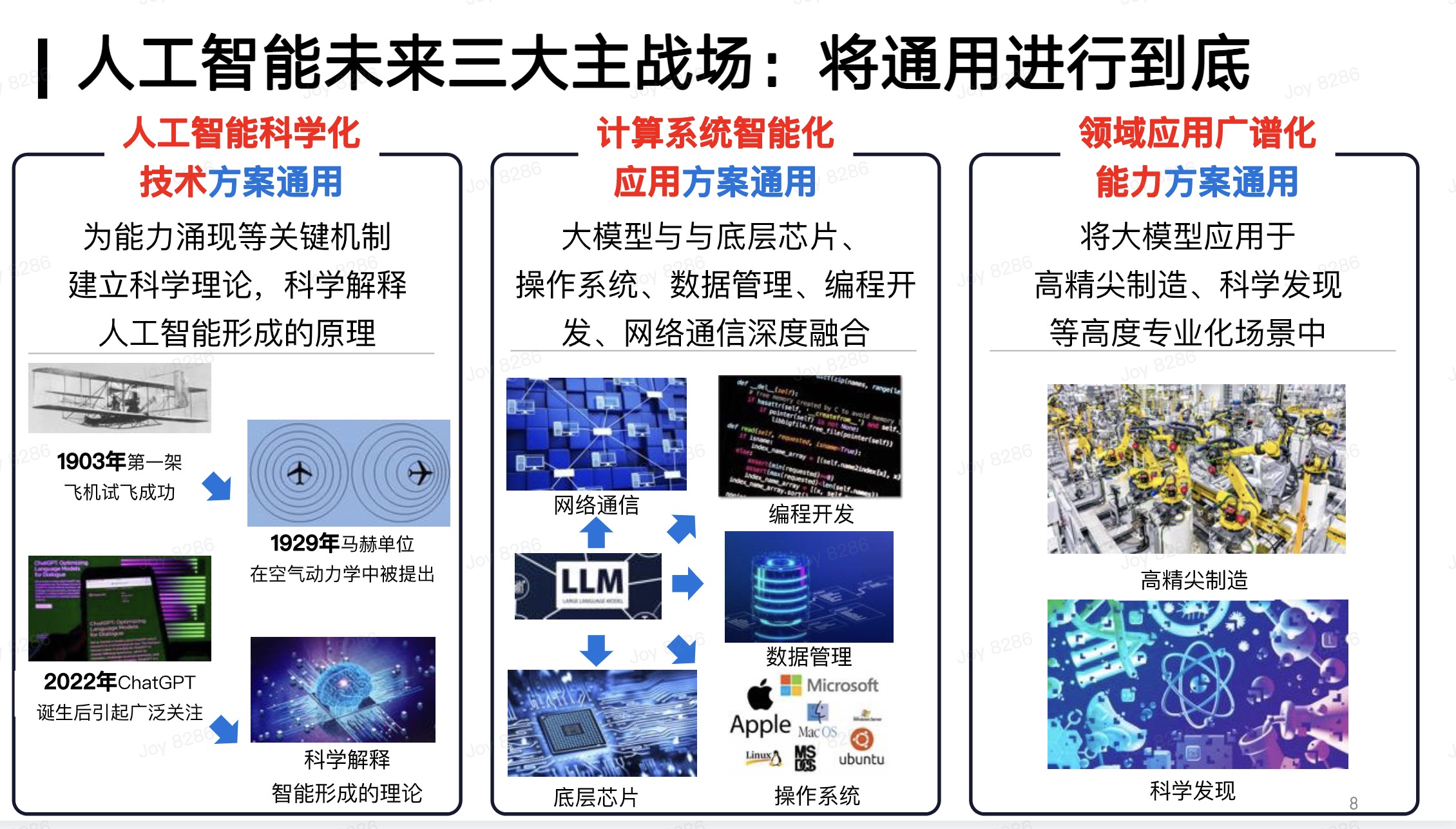
面向未来,我们认为人工智能有三大主战场,它们的目标都是让通用人工智能达到顶尖水平。首先,我们要探索人工智能的科学化技术方案,实现更科学、更高效的人工智能实现方式。其次,我们要实现计算系统的智能化,能够在计算层面以更低的成本、更通用地将大模型应用于各个领域。最后,我们也要在各个领域探索人工智能的广谱化应用。
以下是观众提问环节:
OpenAI犯了“傲慢之罪”
Q: DeepSeek的成功因素里,最有亮点的一个技术是什么?
刘知远:我觉得主要有两条启示:DeepSeek V3给我们的重要启示在于,它展示了如何用1/10甚至更少的成本完成达到GPT-4和GPT-4o水平的能力。DeepSeek V3在底层算力加速方面做了大量工作。但更重要的是,翟老师特别强调了DeepSeek V3实现了算法和底层软硬件的协同优化。这种一体化优化机制让大家看到,即使成本已经很低,但仍然可以通过优化进一步降低成本。虽然V3的成本仍然是几百万美元甚至几千万美元,但相比国际上公认的水平,已经低得多。这也是英伟达股价下降的一个重要原因。
DeepSeek R1的启示在于,OpenAI犯了“傲慢之罪”——它不开源,不公开技术细节,且定价过高。而DeepSeek的R1则开源且免费,让全球用户都能使用,并且公开了所有技术细节。这使得DeepSeek在历史上占据了原本应该属于OpenAI的位置,就像当年的ChatGPT一样。DeepSeek通过极致优化有限资源,成功追赶上了国际最先进的模型,我觉得干的非常漂亮,并且通过开源让全球都认识到中国团队的创新能力。
Q:为什么DeepSeek的 R1模型在这个时间点出现?之前有没有基于基础模型直接做强化学习的尝试?之前也有模型在思维链上做过类似工作,为什么DeepSeek的R1模型会如此出圈?
刘知远:我觉得这件事情还是具有一定的必然性。大概在2024年的时候,很多投资人,甚至一些不从事人工智能领域的人,会来问我:中国的AI和美国的AI相比,到底是差距变大了还是变小了?我当时明确表示,我们认为中国正在非常快速地追赶,与美国最先进的技术之间的差距正在逐渐缩小。尽管我们面临一些限制,但这种追赶是显而易见的。
一个重要的现象可以验证这一点:2023年初ChatGPT和后面GPT-4发布后,国内团队复现这两个版本的模型大概都花了一年时间。2023年底,国内团队复现了ChatGPT水平的模型能力;2024年四五月份,一线团队复现了GPT-4水平的能力。但随后你会发现,像Sora、GPT-4o这样的模型,基本上都是国内团队在大约半年内完成复现的。这意味着,像o1这样的模型能力,国内团队在半年左右复现是可预期的。
DeepSeek本身非常出色,其价值不仅在于能够复现,还在于它以极低的成本做到了这一点。这是它的独到之处,也是它脱颖而出的原因。但无论如何,国内一线团队能够在半年左右复现o1水平的模型能力,我认为这是可以预期的。DeepSeek能够更快、更低成本、更高效地完成这项工作,这是它的巨大贡献。从这个角度看,我认为有一定的必然性。
当然,DeepSeek能够达到这样的出圈效果,也离不开它自身团队的长期积累,这正如刚才邱锡鹏老师提到的那样。
Q:(评论区问题)刚刚知远老师 PPT 里提到的能力密度是如何定义的?它的内在原因是什么?
刘知远:这个“能力密度”的概念是我们最近半年提出的。关于如何有效地、准确地衡量能力密度,大家可以参考我们发表在arxiv 上的论文,论文题目是《Densing law of LLMs》。
所谓的能力密度,可以理解为模型在各种评测集上展现出来的能力,除以其参数规模,或者说是激活的参数规模。我们观察过去一年半发布的代表性模型,发现其能力密度大约每100天增加一倍。这意味着每过100天,我们可以用一半的参数实现相同的能力。这一现象背后有多个因素影响:
·1数据质量:更高的数据质量取决于数据治理。高质量的数据能够提升模型的训练效果。
·2模型架构:采用更稀疏激活的模型架构,可以用更少的激活参数承载更多的能力。
·3学习方法:包括OpenAI在内的所有一线团队都在开展所谓的“scaling prediction”。在真正训练模型之前,我们会进行大量的风洞实验,积累各种预测数据,以确定模型需要什么样的数据配比和超参配置,从而达到最佳效果。
综合这些因素,模型可以用更少的参数承载更多的能力。我们将这一现象类比为芯片行业的摩尔定律。摩尔定律告诉我们,每18个月,芯片上的电路密度会增加一倍。这一过程是通过不断的技术发展实现的。
进一步结合刚才翟老师和国浩老师提到的底层算力优化,我们可以将这种优化映射到模型训练阶段,从而极大地降低成本。当然,我们并不是说DeepSeek的算力可以用1/10的成本实现与国外模型相同的能力,但这与Densing law(能力密度定律)有一定的重叠。
Densing Law更多地强调模型密度的不断提高,这不仅体现在训练阶段成本的降低,也体现在推理阶段。模型可以用更低的推理成本和更快的推理速度完成相同的能力。我们认为,未来AI的发展一定会沿着这条路线前进。过去几年的发展也在不断验证这一点。一个直观的体验是,像OpenAI这样的公司,其API模型的价格(例如 ChatGPT 水平的模型和GPT-4水平的模型)在过去几年中快速下降。这不仅仅是因为价格战,而是因为它们可以用更少的资源实现相同的能力,从而以更低的成本提供服务。
我们认为,高效性是未来AI发展的一个重要方向,也是我们迎来智能革命的一个重要前提。
Q: MoE架构会是通向AGI道路上的最优解吗?
刘知远:我的个人感觉是,其实没有人永远是对的。
在2023年初,OpenAI发布ChatGPT时,它做对了;它发布GPT-4时,也做对了。但当它发布o1时,它做错了——它没有开源,定价策略也出现了失误。这反而成就了DeepSeek。我也不认为DeepSeek选择了MoE架构,MoE就永远是正确的。没有任何证据证明MoE是最优的模型架构。
从学术角度和AI未来发展的角度来看,我认为这是一个开放性的问题。未来如何实现高效性?我认为一定是模块化和稀疏激活的,但具体如何稀疏激活、如何模块化?我觉得这件事情本身应该是百花齐放的。我们应该保持开放性,鼓励学生和从业者像DeepSeek一样努力去探索创新。
所以,我本身不太认为MoE有任何绝对的壁垒,或者它一定是最优的方法。
DeepSeek所做的工作可能也是“摸着OpenAI过河”
Q:DeepSeek技术的爆发,对于中国大模型未来发展道路有哪些启示?
刘知远:首先,我觉得特别值得敬佩的是DeepSeek团队的技术理想主义。因为无论是看他们的访谈还是其他资料,你会发现,那些访谈其实是在DeepSeek大火之前很久接受的,内容非常真实,能够反映他们内在的底层逻辑。从这一点上,我们可以感受到DeepSeek是一个非常具有技术理想主义的团队,以实现 AGI 作为梦想来组建这个团队。我觉得这一点是非常值得敬佩的。
我觉得同时也会看到,DeepSeek的梁文峰之前做量化投资,本身投入自己的资金来开展项目,没有资金上的困扰。那么相对应地,我觉得中国应该为这样的技术理想主义团队提供支持,哪怕他们没有足够的资金,也能让他们没有后顾之忧地去进行探索。我觉得中国已经到了这样的阶段,需要有更多像DeepSeek这样的团队,但又不像DeepSeek这样有资金。能否让他们踏踏实实地去做一些原始创新,做一些出色的工作,这是我觉得非常值得我们思考的第一点。
第二点,我觉得是他们的执行力。DeepSeek今年这两个月一炮而红,大家会觉得很厉害,但实际上,这是经过了多年持续积累的结果。我们看到的是他们不断积累的进步,量变最终产生了质变。我可以告诉大家,几年前,幻方就拿着免费算力去吸引我们的学生,与他们建立联系。当然,也有学生毕业后加入了DeepSeek。所以,这是他们多年努力的结果。我认为这也是技术理想主义推动下的长期主义成果。我觉得国内应该有更多的团队,能够坐得住冷板凳,更加聚焦,在一些重要问题上持续发力,做出有意义的工作。
DeepSeek发展到今天,我认为他们所做的工作可能也是在“摸着OpenAI过河”,以OpenAI为榜样,去探索AGI的实现路径,并努力去做他们认为正确的事情。这个过程非常困难,尤其是随着OpenAI变得越来越封闭,o1复现的难度比当年的ChatGPT更大。但我们会看到,只要有理想和执行力,他们就能做到。所以在我看来,国内应该有更多的团队去学习。具体的技术当然是我们应该学习的一部分,但我觉得应该避免认为因为DeepSeek成功了,所以他们所做的一切都是对的。我觉得不一定他们所用的所有技术都是最先进的。我觉得没有必要因为DeepSeek这次成功用了这样那样的技术,就认为它们全都是对的。我觉得这反而会限制我们的创新。我觉得我们应该学习的是他们的理想,学习的是他们的坚持,学习的是他们的方法论。这是我想分享的第二点。
相关文章
-

最高追击令:黑料吃瓜网-热点事件-黑料不打烊-美国务院:美政府船只现在可以免费通过巴拿马运河
-
继承者们第8集:美女被强奷到抽搐的动态图-刘知远详解DeepSeek出圈背后的逻辑:自身算法的创新以及OpenAI的傲慢
-
美国取消800美元以下商品关税豁免,跨境电商:影响多大还不明晰
-
一级久久:黑料不打烊网页版入口-美财长:财政部支付系统不受马斯克政府效率部影响
-
黑暗正能量index.php2024:空姐前规则免费观看-两次计划访美未果,石破茂终于开启“弹丸行程”
-
老师你的兔子好软水好多在线看:黑户网-开年即冲刺!三个关键词看上海开工首日
-
国办:禁止向电商平台颁发成品油零售经营批准证书
-
你为我着迷4:双汇接班人的“权力游戏”-盘中必读|今日共83股涨停,沪指震荡收跌0.65%,DeepSeek概念集体大涨





